
昨天的最後說明了我是如何定義一篇網路政治新聞的 Data Class,但是問題來了,這些政治新聞 Data Class 中所包含的資訊要以什麼樣的形式儲存?要用資料科學常見的 .csv?還是存成 .json 檔案?又或者有其他更適合的方案呢?
我對於「基於自然語言處理的新聞意見提取應用」當中的新聞資料與儲存方式有如下幾點期望:
由於希望「基於自然語言處理的新聞意見提取應用」是個長期的專案,「自動更新獲取最新的新聞文章」會在經過一段時日後累積大量的新聞內容,每天可從多個新聞網站搜集超過一百篇的新聞,如果以 .csv 或 .json 檔案儲存,可能需要存成很多個檔案,或是數個大小很大的檔案。若是存成很多個檔案,即便可以用檔案命名規則或資料夾結構達到初步的新聞資料分類,但之後的程式碼要透過條件查找目標資料會相當不方便(e.g. 找尋帶有特定 hash tag 的新聞資料)。反之如果是存成數個大小很大的檔案,依照我之前讀取有很多 row 的 .csv 檔案的經驗,若是使用 pandas (Python)套件來讀取可能會需要數十秒或更久,不是很有效率的做法。
基於以上理由我決定採用資料庫管理工具,來幫助我儲存蒐集到的新聞資料。接下來將介紹我採用的方案,以 AWS 的 Amazon Aurora Serverless 服務,建立 PostgreSQL 資料庫。
考量到需要「自動更新獲取最新的新聞文章」以及「方便讓網頁應用讀取」,就需要一個隨時都能新增、讀取新聞資料的方案,如果要租用雲端服務就需要另外考慮到這樣的需求所帶來的成本能否負荷。在 AWS 上有許多不同的資料儲存方案,單就資料庫就有關聯性與非關聯性可選。基於昨天設計好的新聞資料蠻容易就可以轉換成可以 table 方式儲存的格式,所以可以使用 AWS RDS(relational database service)服務,而其正好有個乍看每小時收費成本較低的無伺服器(Serverless)方案(是否比較划算可能還需要更進一步計算),還可以自行選用要 PostgreSQL 或 MySQL 系統,而我最後選了 PostgreSQL 。
這裡引用 1. 什麼是 PostgreSQL? 當中的介紹
PostgreSQL 是美國加州伯克萊大學資訊科學系基於 POSTGRES 4.2 所研發的物件關聯式資料庫管理系統(ORDBMS, Object-Relational Database Management System)。POSTGRES 中的許多重要概念成為日後一些商用資料庫系統重要的一部份。
PostgreSQL 由伯克萊大學公開其原始碼所誕生,它支援了大多數的標準 SQL 語法,並提供許多先進的功能:
- 複雜查詢(complex queries)
- 外部索引鍵(foreign keys)
- 觸發器(triggers)
- 可更新檢查表(updatable views)
- 事務完整性(transactional integrity)
- 多版本併行控制(multiversion concurrency control)
同時,PostgreSQL 也支援讓使用者能以自己的方式進行擴充。比如透過新增:
- 資料型別(data types)
- 函數(functions)
- 操作(operators)
- 聚合函數(aggregate functions)
- 索引方法(index methods)
- 過程式語言(procedural languages)
並且基於自由許可證,任何人都能夠以任何目的,免費地使用、修改、與散布 PostgreSQL,不論是個人使用、商業用途還是學術研究。
上述的眾多先進功能對於我這個資料庫新手來說可能暫時不會用到,想要的功能應該用標準 SQL 語法就夠了。另外一個 PostgreSQL 吸引我的點是在 PostgreSQL vs MySQL 中的一段敘述,敘述如下:
NoSQL 和 JSON 都非常流行,NoSQL資料庫變得越來越普及。JSON 是一種簡單的資料格式,它允許程式設計師儲存和傳遞跨系統的資料內容、資料列表和 key-value 對應。(在 NoSQL 和 JSON 項目上比對如下表)
| PostgreSQL | MySQL |
|---|---|
| PostgreSQL 支援 JSON 和其他 NoSQL 的功能,如內建 XML 支援和 HSTORE 的 key-value 對應。 它還支援將 JSON 資料索引以加快存取速度。 | MySQL 具有 JSON 資料類型支援,但沒有其他 NoSQL功能,也不支援 JSON 索引。 |
因為昨天所定義的新聞 Data Class(NewsData)中,在圖片與 hash tag 資料是另外用 Data Class 定義的子結構,如果將這些子結構的 Data Class 轉換成 json 資料儲存在 table 結構當中,便可以利用 Postgres 的 json 資料索引功能。另外,也許後續會在開發新聞應用時可以看情況使用 NoSQL 的功能。綜合上述原因我最終才決定採用 PostgreSQL 而不是 MySQL。
下面敘述引用 1.2. 基礎架構
以資料庫的術語來說,PostgreSQL 採用了主從式架構(client/server)。PostgreSQL 會在進行下列操作時保持連線:
- 伺服器的執行程序,負責管理資料庫的檔案、受理用戶端的連線要求、執行相對應的資料庫動作。這樣的資料庫伺服端程式稱之為「postgres」。
- 用戶端的程式用來發起資料庫操作的行為,其設計的形態很廣泛:可能是文字介面的工具、圖型介面的程式、將資料庫內容顯示成網頁的網際網路伺服器、甚或是專用的資料庫管理工具。有一些用戶端程式是由 PostgreSQL 官方所提供,大部份由第三方的其他使用者所開發。
如同一般的主從式架構,用戶端與伺服端可以是兩台不同的主機,而他們透過 TCP/IP 的網路協定溝通。你應該將這個觀念謹記在心,因為某些在用戶端可以被存取的檔案,在伺服端可能就無法存取(或使用不同的檔案名稱)。
可以從 PostgreSQL Downloads上找到適合自己作業系統的安裝方式,注意有提供不同的版本。(我是用跟 Amazon Aurora Serverless 上自行設定相同的 PostgreSQL 14,下一段中會提到)
安裝完成後可以在終端機輸入以下指令進行確認:
$ psql --version
psql (PostgreSQL) 14.4
Amazon Aurora
Amazon Aurora 是一項專為雲端建置的關聯式資料庫管理系統 (RDBMS),與 MySQL 和 PostgreSQL 完全相容。
Amazon Aurora Serverless
Amazon Aurora Serverless 是 Amazon Aurora 的隨需、自動調整規模組態。它可根據應用程式的需要而自動啟動、關閉和擴展或縮減容量。它可讓您在雲端執行資料庫,無須管理任何資料庫容量。
手動管理資料庫容量需花費寶貴的時間,而且可能導致資料庫資源使用效率不良的情況。使用 Aurora Serverless,只要建立資料庫端點、選擇性指定所需的資料庫容量範圍,然後連結應用程式即可。資料庫啟動之後,您只需支付所用資料庫容量的每秒費率,然後在 Amazon RDS 管理主控台按幾下,即可在標準和無伺服器組態間遷移。
下面列出一些我比較看重的 Amazon Aurora Serverless 特性:
以下內容引用 Amazon Aurora 常見問答集
Amazon Aurora 與 PostgreSQL 是否相容?
Amazon Aurora 與現有的 PostgreSQL 開源資料庫直接相容,並定期新增對新版本的支援。這意味著您可以使用標準匯入/匯出工具或快照輕鬆地將 PostgreSQL 資料庫遷移至 Aurora 或從 Aurora 遷移。
Amazon Aurora 的費用為何?
對於已佈建的 Aurora,您可以選擇隨需執行個體並按小時支付資料庫費用,無需長期承諾或預付費用,或者選擇預留執行個體以節省額外費用。或者,Aurora Serverless 可根據應用程式的需要自動啟動、關閉和擴展或縮減容量,您僅需按耗用的容量付費。
Aurora Serverless 如何計費?
在 Aurora Serverless 中,資料庫容量以 Aurora 容量單位 (ACU) 計算。按每秒 ACU 用量的固定費率付費。儲存和 I/O 價格與佈建和無伺服器組態相同。瀏覽 Aurora 定價頁面,以了解有關定價和 AWS 區域可用性的最新資訊。
Aurora Serverless 用分 v1 和 v2,在 Aurora 定價頁面 中的價格並沒有差太多,而 v2 與 v1 之間有何差異可以參考下方的補充。目前我使用 Serverless v2 的新聞資料庫每日成本約 1.5 美元(2022/09/21 根據專案狀態及 AWS 定價的參考價格,依你的使用場境可能會有所不同)。
Aurora Serverless v2 與 v1 之間有何差異?
從開發、測試環境、網站和工作負載,以及具有不頻繁、間歇或不可預測工作負載的應用程式,到需要高度擴展、高可用性的要求最嚴苛的業務關鍵型應用程式,Aurora Serverless v2 支援各種類型的資料庫工作負載。它透過新增更多 CPU 和記憶體來進行適當擴展,而無需將資料庫容錯移轉至更大或更小的資料庫執行個體。因此,即使存在長時間執行的交易、資料表鎖定等,它也可以擴展。
此外,它還能以低至 0.5 個 Aurora 容量單位 (ACU) 的增量擴展資料庫容量,因此您的資料庫容量接近符合您的應用程式需求。
Aurora Serverless v1 為不頻繁、間歇或不可預測的工作負載提供了一種簡便、經濟高效的選擇。它會自動啟動、擴展運算容量以符合您的應用程式的用量,並在不使用時關閉。請瀏覽《Aurora 使用者指南》以進一步了解相關資訊。
Aurora Serverless v2 支援哪些 Aurora 功能?
Aurora Serverless v2 支援已佈建 Aurora 的所有功能,包括僅供讀取複本、多可用區域組態、全域資料庫、RDS 代理和 Performance Insights。
如何連接到 Aurora Serverless 資料庫叢集?
您可以從同一個 VPC 中執行的用戶端應用程式存取 Aurora Serverless 資料庫叢集。您無法為 Aurora Serverless 資料庫提供公有 IP 地址。
以下內容參考 建置無伺服器應用程式 利用 Amazon Aurora Serverless 實現,我將此 MySQL 教學改成 PostgreSQL。
開啟瀏覽器並瀏覽至 Amazon RDS 主控台。如果您已有 AWS 帳戶,請登入主控台。否則,請建立新的 AWS 帳戶來開始使用。
在右上角選擇您希望啟動 Aurora 資料庫叢集的區域。(e.g. 維吉尼亞洲北部,地區不同價格也不一樣)
在「Amazon RDS」左側選單中點選 「資料庫(database)」,再點選頁面中橘色的「建立資料庫 (create database)」。
勾選「標準建立」。
按圖片中設定「引擎選項」。
「範本」中勾選「開發/測試」。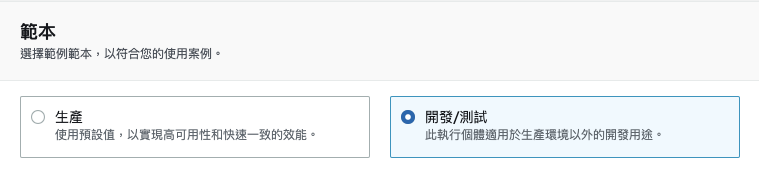
設定「DB cluster identifier (資料庫叢集識別符)」、「主要使用者名稱」、「主要密碼」。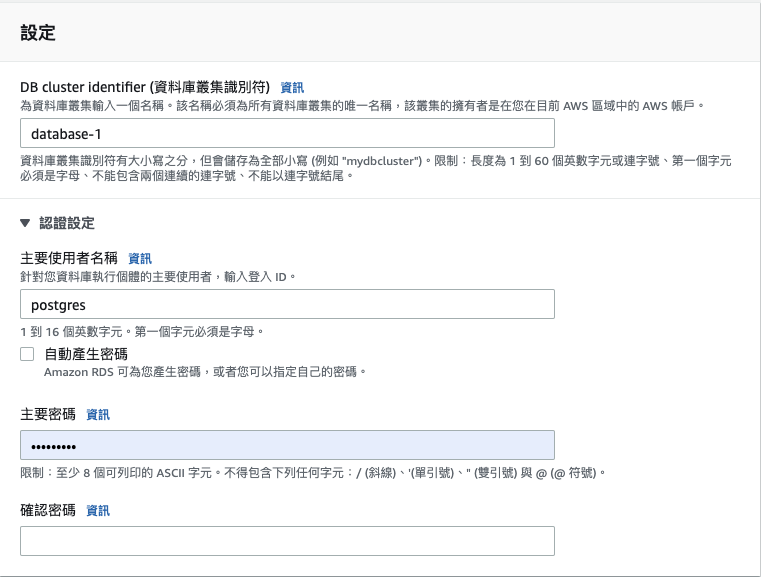
在「執行個體組態」中勾選「無伺服器」、「Serverless v2」,並設定「最小 ACU
=0.5」、「最大 ACU=1」(此處設定關係到後續的收費價格,只後還可更改)。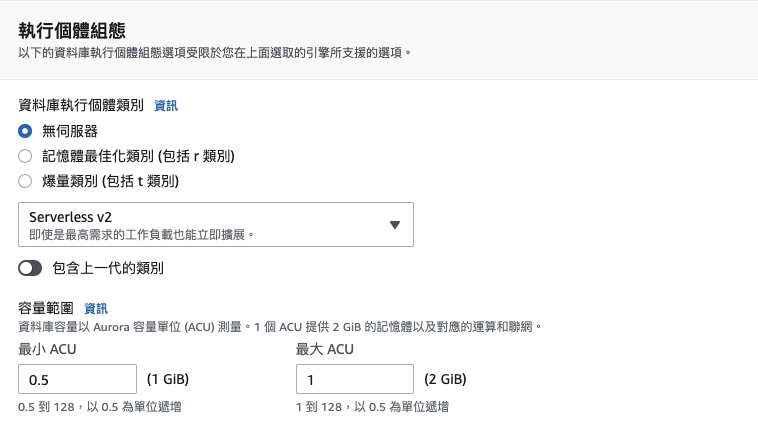
「可用性與持久性」勾選「請不要建立 Aurora 複本」。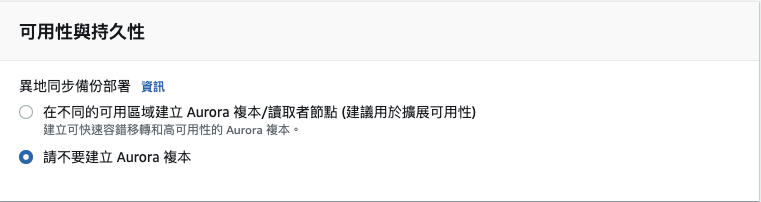
「連線」中勾選 「不要連接至 EC2 運算資源」、「
IPv4」、「公開存取(讓你的電腦也可以連線)」,同時完成 PVC 設定(如果是第一次,頁面會引導你建立 default),最後「資料庫連接埠」維持預設的「5432」。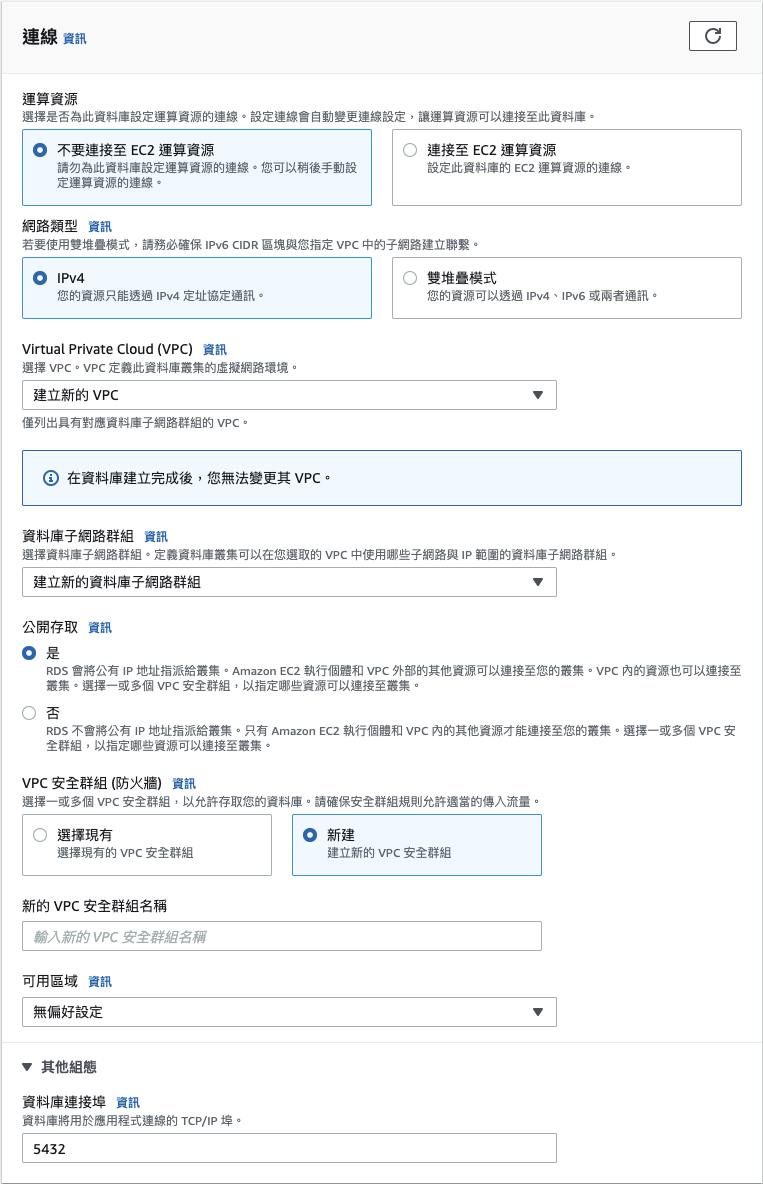
「資料庫身份驗證」中勾選「密碼身份驗證」。
在「其他組態中」,輸入「初始資料庫名稱」,此為自行定義的資料庫名稱(這裡用 mydatabase 做示範)。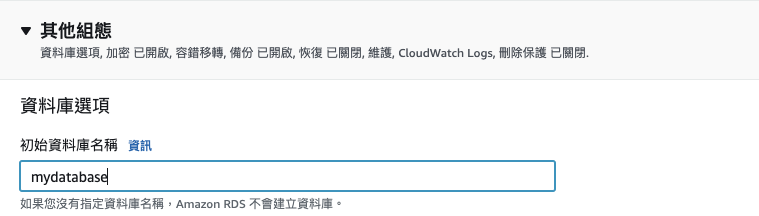
其餘設定維持預設值就可以了。
點選頁面最下方橘色的「建立資料庫」,建立過程需要等待一段時間(可能十多分鐘),可以透過在「Amazon RDS」左側選單中點選 「資料庫(database)」,在頁面中查看資料庫的狀態(正在建立還是已完成或失敗)。
注意:上面的設定只是範例,可以依照你的使用需求做出調整。
到這裡就完成設定了!
2.2. Concepts 中有這麼一段描述:
Tables are grouped into databases, and a collection of databases managed by a single PostgreSQL server instance constitutes a database cluster.
也就是說整體結構如下:
在上一段的教學操作中已經建立好 database cluster 和 databases,接下來就要在剛剛建立的 databases 中建立以個 table,用來儲存蒐集到的新聞資料。
連線到資料庫的方式有很多種,可以透過終端機執行指令、python 的 psycopg 套件以及 PgAdmin 視窗圖形界面等,這裡先介紹透過終端機執行指令的方法。
如果在下方的操作中無法從你的個人電腦連線到資料庫
請參考無法連接至 Amazon RDS 資料庫執行個體,按照其指示設定 VPC 的 IP 連線權限。
這裡希望建立一個 table 來儲存昨天定義的新聞 Data Class 內的資訊。根據新聞的 Data Class 裡的 instance attribute 的類別(type),對照 PostgreSQL 的資料型別,我設計了下面的 create_table.sql 來建立用來儲存新聞的 table。
注意:在此範例中
create_table.sql存在與終端機目前相同的路徑。
CREATE TABLE if NOT EXISTS newstable (
time timestamptz,
source text,
category text,
author text,
title text,
content text[],
url text,
images json[],
hash_tags json[],
);
SET TIME ZONE 'Asia/Taipei';
上面程式碼的註解:
CREATE TABLE if NOT EXISTS newstable 將建立名為 newstable 的 table,如果目前沒有同名 table 存在的話。newstable (...) 的括號中描述了 column 的名稱與資料類型(type),可以對照資料型別。SET TIME ZONE 'Asia/Taipei' 設定時區為 Asia/Taipei。其他 SQL 語法
可以參考教學 II. SQL 查詢語言
將下方指令帶入你的資料庫資訊,再到終端機中執行指令:
USER-PASSWORD 須待換成資料庫建立時設定的使用者密碼。HOSTNAME :在「Amazon RDS」左側選單中點選 「資料庫(database)」,再點選頁面中你的 database instance,可以在跳轉的頁面中的「連線與安全性」>「端點與連接埠」>「端點」找到一串 ....rds.amazonaws.com。PORT 須待換成資料庫建立時設定的 port(e.g. 5432)USERNAME 須待換成資料庫建立時設定的著要使用者名稱(e.g. postgres)DBNAME 須待換成資料庫名稱(e.g. mydatabase)./create_table.sql 可以換成任何要執行的 SQL 檔案PGPASSWORD=USER-PASSWORD psql -h HOSTNAME -p PORT -U USERNAME -d DBNAME -f ./create_table.sql
由於後續將使用 Python 來完成「新增新聞資料」、「讀取新聞資料」等任務,所以需要用到 psycopg 套件來輔助。 psycopg 同樣具備連線到資料庫並執行 SQL 的功能,並且能輕易在 Python 與 PostgreSQL 的資料類型(type)間轉換。
由於之後會將帶有 psycopg 的 Python 程式碼成 Docker container,在沒有先安裝 PostgreSQL 的情況下,需要選擇安裝二進制的版本,安裝指令如下:
pip install "psycopg[binary]"
也可以在前幾天介紹的 Pipenv 建立的虛擬環境中安裝:
pipenv install psycopg[binary]
下方程式碼取自 Basic module usage 的範例
# Note: the module name is psycopg, not psycopg3
import psycopg
# Connect to an existing database
with psycopg.connect("dbname=test user=postgres") as conn:
# Open a cursor to perform database operations
with conn.cursor() as cur:
# Execute a command: this creates a new table
cur.execute("""
CREATE TABLE test (
id serial PRIMARY KEY,
num integer,
data text)
""")
# Pass data to fill a query placeholders and let Psycopg perform
# the correct conversion (no SQL injections!)
cur.execute(
"INSERT INTO test (num, data) VALUES (%s, %s)",
(100, "abc'def"))
# Query the database and obtain data as Python objects.
cur.execute("SELECT * FROM test")
cur.fetchone()
# will return (1, 100, "abc'def")
# You can use `cur.fetchmany()`, `cur.fetchall()` to return a list
# of several records, or even iterate on the cursor
for record in cur:
print(record)
# Make the changes to the database persistent
conn.commit()
with psycopg.connect("dbname=test user=postgres") as conn用來建立連線,要連結到剛剛建立在 AWS 的資料庫需要改成下面的方案(conninfo 中的字串要做與上一段「連線到資料庫並執行 SQL」中相同的代換):
conninfo = "host=HOSTNAME dbname=DBNAME port=PORT user=USERNAME password=USER-PASSWORD"
with psycopg.connect(conninfo) as conn:
cur.execute() 用來執行 SQLcur.fetchone()、cur.fetchall() 用來提取cur.execute() 執行的結果,做以下更動可以讓其結果變成更好處理的 Python dict 類型:
from psycopg.rows import dict_row
with conn.cursor(row_factory=dict_row) as cur:
conn.commit() 用來依照先前的操作更新資料庫其他 psycopg 的用法請參考:Psycopg 3 – PostgreSQL database adapter for Python
除了透過終端機指令或寫 Python 程式的方式外,也可以透過 PgAdmin 以圖形化操作的方式操作 PostgreSQL 資料庫。
從這裡 Download選擇適合的安裝方式。
如圖在 Servers 「點選右鍵」> Register > Server
在 General 選單中的 Name,輸入一個你的 Server 名稱(e.g. database_1)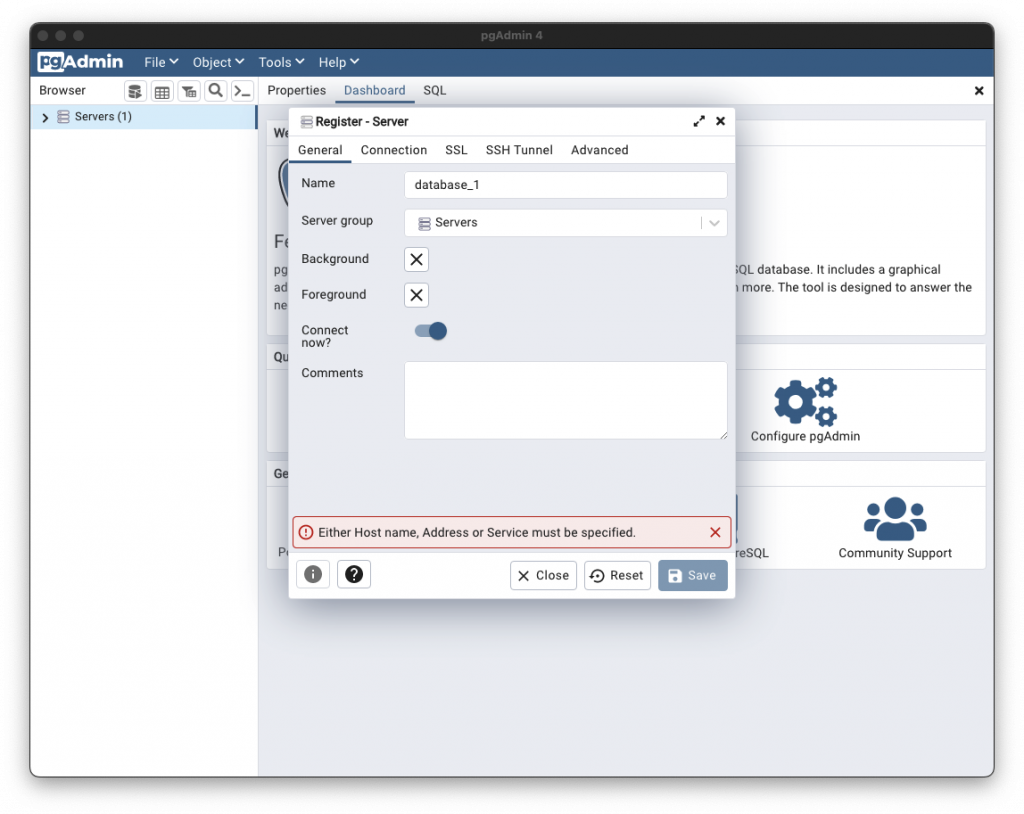
在 Connection 選單中,填入(請對照下面代換註解):
HOSTNAME
PORT
USERNAME
USER-PASSWORD
代換註解
-USER-PASSWORD須待換成資料庫建立時設定的使用者密碼。
-HOSTNAME:在「Amazon RDS」左側選單中點選 「資料庫(database)」,再點選頁面中你的 database instance,可以在跳轉的頁面中的「連線與安全性」>「端點與連接埠」>「端點」找到一串 ....rds.amazonaws.com。
-PORT須待換成資料庫建立時設定的 port(e.g. 5432)
-USERNAME須待換成資料庫建立時設定的著要使用者名稱(e.g. postgres)
那麼今天的內容就先到這裡,希望我的說明能幫到需要的人。
寫的有些匆忙,如果文章有錯誤,歡迎指正~
